
La correzione automatica, o testo predittivo, è una caratteristica comune di molti strumenti tecnologici moderni, dalle ricerche su Internet alle app di messaggistica e agli elaboratori di testi. La correzione automatica può essere una benedizione, ma quando l’algoritmo commette errori può cambiare il messaggio in modi drammatici e talvolta esilaranti.
La nostra ricerca mostra che gli errori di correzione automatica, in particolare nei fogli di calcolo Excel, possono anche creare confusione nei nomi dei geni nella ricerca genetica. Abbiamo esaminato più di 10.000 documenti con elenchi di geni Excel pubblicati tra il 2014 e il 2020 e abbiamo scoperto che più del 30% conteneva almeno un nome di gene alterato dalla correzione automatica.
Questa ricerca segue il nostro studio del 2016 che ha rilevato che circa il 20% dei documenti conteneva questi errori, quindi il problema potrebbe peggiorare. Crediamo che la lezione per i ricercatori sia chiara: è ora di smettere di usare Excel e imparare a usare software più potenti.
Excel fa supposizioni errate
I fogli di calcolo applicano il testo predittivo per indovinare quale tipo di dati desidera l’utente. Se digiti un numero di telefono che inizia con zero, lo riconoscerà come valore numerico e rimuoverà lo zero iniziale. Se digiti “=8/2”, il risultato apparirà come “4”, ma se digiti “8/2” verrà riconosciuto come una data.
Con i dati scientifici, il semplice atto di aprire un file in Excel con le impostazioni predefinite può danneggiare i dati a causa della correzione automatica. È possibile evitare la correzione automatica indesiderata se le celle sono preformattate prima di incollare o importare i dati, ma questo e altri suggerimenti per l’igiene dei dati non sono ampiamente praticati.
In genetica, è stato riconosciuto nel lontano 2004 che Excel avrebbe probabilmente convertito in date circa 30 nomi di geni e proteine umani. Questi nomi erano cose come MARCH1 , SEPT1 , Oct-4 , jun e così via.
Diversi anni fa, abbiamo individuato questo errore nei file di dati supplementari allegati a un articolo di giornale ad alto impatto e ci siamo interessati a quanto siano diffusi questi errori. Il nostro articolo del 2016 indicava che il problema riguardava riviste di livello medio e alto a tassi più o meno uguali. Questo ci ha suggerito che i ricercatori e le riviste erano in gran parte inconsapevoli del problema della correzione automatica e di come evitarlo.
Come risultato del nostro rapporto 2016, lo Human Gene Name Consortium, l’organismo ufficiale responsabile della denominazione dei geni umani, ha ribattezzato i geni più problematici. MARCH1 e SEPT1 sono stati modificati rispettivamente in MARCHF1 e SEPTIN1 e altri hanno avuto cambiamenti simili.
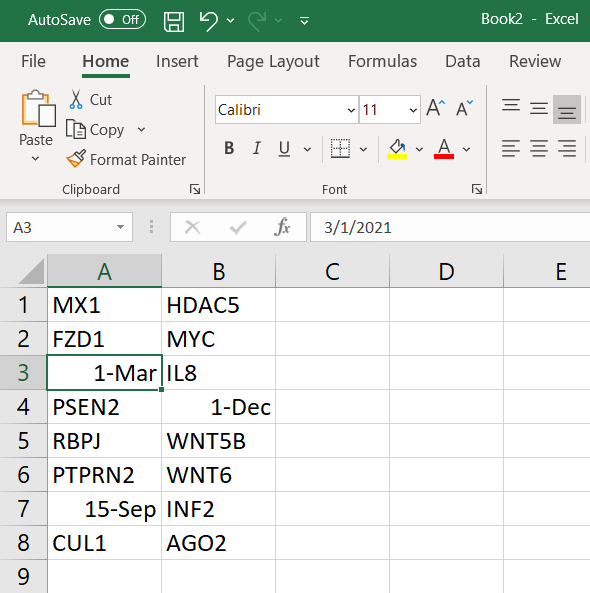
Un problema in corso
All’inizio di quest’anno abbiamo ripetuto la nostra analisi. Questa volta l’abbiamo ampliato per coprire una selezione più ampia di riviste ad accesso aperto, anticipando che ricercatori e riviste avrebbero adottato misure per evitare che tali errori appaiano nei loro file di dati supplementari.
Siamo rimasti scioccati nello scoprire nel periodo 2014-2020 che 3.436 articoli, circa il 31% del nostro campione, contenevano errori nei nomi dei geni . Sembra che il problema non sia scomparso e stia effettivamente peggiorando.
I piccoli errori contano
Alcuni sostengono che questi errori non contano davvero, perché circa 30 geni sono solo una piccola frazione dei circa 44.000 dell’intero genoma umano, ed è improbabile che gli errori si capovolgano alle conclusioni di un particolare studio genomico.
Chiunque riutilizzi questi file di dati supplementari troverà questo piccolo insieme di geni mancante o danneggiato. Questo potrebbe essere irritante se il tuo progetto di ricerca esamina la famiglia di geni SEPT , ma è solo una delle tante famiglie di geni esistenti.
Crediamo che gli errori siano importanti perché sollevano domande su come questi errori possono intrufolarsi nelle pubblicazioni scientifiche. Se gli errori di correzione automatica del nome del gene possono passare la revisione paritaria non rilevata nei file di dati pubblicati, quali altri errori potrebbero essere in agguato tra le migliaia di punti dati?
Catastrofi dei fogli di calcolo
Negli affari e nella finanza, ci sono molti esempi in cui gli errori dei fogli di calcolo hanno portato a perdite costose e imbarazzanti .
Nel 2012, JP Morgan ha dichiarato una perdita di oltre 6 miliardi di dollari grazie a una serie di errori commerciali resi possibili da errori di formula nei suoi fogli di calcolo di modellazione. L’analisi di migliaia di fogli di calcolo presso la Enron Corporation, prima della sua spettacolare caduta nel 2001, mostra che quasi un quarto conteneva errori .
Un articolo ormai famigerato degli economisti di Harvard Carmen Reinhart e Kenneth Rogoff è stato utilizzato per giustificare i tagli all’austerità all’indomani della crisi finanziaria globale, ma l’analisi conteneva un errore critico di Excel che ha portato a omettere cinque dei 20 paesi nella loro modellazione.
Proprio l’anno scorso, un errore del foglio di calcolo presso Public Health England ha portato alla perdita di dati corrispondenti a circa 15.000 casi positivi di COVID-19. Ciò ha compromesso gli sforzi di tracciamento dei contatti per otto giorni mentre i numeri dei casi stavano crescendo rapidamente. In ambito sanitario, gli errori di immissione dei dati clinici nei fogli di calcolo possono raggiungere il 5%, mentre uno studio separato sui fogli di calcolo dell’amministrazione ospedaliera ha mostrato che 11 su 12 contenevano difetti critici.
Nella ricerca biomedica, un errore nella preparazione di un foglio campioni ha comportato lo spostamento di un intero set di etichette dei campioni di una posizione e la modifica completa dei risultati dell’analisi genomica . Questi risultati erano significativi perché venivano utilizzati per giustificare i farmaci che i pazienti avrebbero ricevuto in una successiva sperimentazione clinica. Questo potrebbe essere un caso isolato, ma non sappiamo davvero quanto siano comuni tali errori nella ricerca a causa della mancanza di studi sistematici di ricerca degli errori.
Sono disponibili strumenti migliori
I fogli di calcolo sono versatili e utili, ma hanno i loro limiti. Le aziende sono passate dai fogli di calcolo a software di contabilità specializzati e nessuno nell’IT utilizzerebbe un foglio di calcolo per gestire i dati quando i sistemi di database come SQL sono molto più robusti e capaci.
Tuttavia, è ancora comune per gli scienziati utilizzare i file Excel per condividere i propri dati supplementari online. Ma poiché la scienza diventa più ad alta intensità di dati e le limitazioni di Excel diventano più evidenti, potrebbe essere il momento per i ricercatori di dare il via ai fogli di calcolo.
Nella genomica e in altre scienze che utilizzano molti dati, i linguaggi per computer con script come Python e R sono chiaramente superiori ai fogli di calcolo. Offrono vantaggi tra cui tecniche analitiche avanzate, riproducibilità, verificabilità e una migliore gestione delle versioni del codice e dei contributi di diversi individui. Potrebbero essere più difficili da imparare inizialmente, ma i benefici per una scienza migliore ne varranno la pena nel lungo periodo.
Excel è adatto all’immissione di dati su piccola scala e all’analisi leggera. Microsoft afferma che le impostazioni predefinite di Excel sono progettate per soddisfare le esigenze della maggior parte degli utenti, la maggior parte delle volte.
Chiaramente, la scienza genomica non rappresenta un caso d’uso comune. Qualsiasi set di dati più grande di 100 righe non è adatto per un foglio di calcolo.
I ricercatori in campi ad alta intensità di dati (in particolare nelle scienze della vita) necessitano di migliori competenze informatiche. Iniziative come Software Carpentry offrono workshop ai ricercatori, ma le università dovrebbero anche concentrarsi maggiormente sul dare agli studenti universitari le capacità analitiche avanzate di cui avranno bisogno.